Asynchronous Implementation of Deep Q-Network
Reinforcement Learning ·In this blog I will share my personal experience of implementing some basic deep learning algorithm asynchronously, including some difficulties I have encountered.
Contents
- Deep Q-Network
- Asynchronous DQN
- Asynchronous Implementation in TensorFlow
- Performance
- Conclusion
- Resources
Deep Q-Network
Deep Q-Network (DQN) is a basic reinforcement learning algorithm that is able to play Atari games with visual input. Its training pipeline is shown below:
- Initialize network variables;
- Initialize the environment;
- Initialize the replay buffer;
- Loop until reaching maximum steps:
- Sample an action using exploration policy;
- Simulate the environemnt with the sampled action;
- Store data into the replay buffer;
- Sample training data from the replay buffer;
- Train the network for one mini-batch.
Asynchronous DQN
Sometimes we want to accelerate the training progress via asynchronous training. The basic idea is to create multiple processes so that the network is shared and trained simultaneously by different processes. The training pipeline of asynchronous DQN is shown below:
- Initialize the global network variables;
- Create N processes;
- For each process do the following simultaneously:
- Initialize a local environment;
- Initialize a local replay buffer;
- Loop until reaching maximum global steps:
- Get a copy of the latest global network;
- Sample an action using exploration policy;
- Simulate the local environment with the sampled action;
- Store data into the local replay buffer;
- Sample training data from the local replay buffer;
- Compute the gradients of the copied network based on the training data;
- Apply the gradients to the global network.
Asynchronous Implementation in TensorFlow
In TensorFlow, asynchronous implementation can be achieved by Distributed TensorFlow. In this blog, I will not go into details as the above link has covered all the basics. Instead, I would like to talk about some common problems I have encountered.
Parameter Server Hanging
This is probably the first problem one will encounter by following the tutorial example. That is, the parameter server process ps will never end even if all the worker processes worker have finished their tasks. The cause of this problem is
if job_name == "ps":
server.join()
When server.join() is executed, ps will be blocked permanently. To solve this problem, ps should be notified whenever a worker has finished its task, and ps should end when all worker have finished their tasks. According to this question, we can modify the codes accrodingly:
if job_name == "ps":
# Parameter server.
with tf.device("/job:ps/task:" + str(task_index)):
queue = tf.FIFOQueue(cluster.num_tasks("worker"), tf.int32, shared_name = "done_queue" + str(task_index))
# Close the parameter server when all queues from workers have been filled.
with tf.Session(server.target) as sess:
for i in range(cluster.num_tasks("worker")):
sess.run(queue.dequeue())
elif job_name == "worker":
# The logic part of a worker.
...
# Execute the following code when a worker finished its job.
queues = []
# Create a shared queue on the worker which is visible on the parameter server.
for i in range(cluster.num_tasks("ps")):
with tf.device("/job:ps/task:" + str(i)):
queue = tf.FIFOQueue(cluster.num_tasks("worker"), tf.int32, shared_name = "done_queue" + str(i))
queues.append(queue)
# Notify all parameter servers that the current worker has finished the task.
with tf.Session(server.target) as sess:
for i in range(cluster.num_tasks("ps")):
sess.run(queues[i].enqueue(task_index))
Memory Allocation of GPU
When I run my initial codes on a GPU server, the server tells me that it cannot allocate extra memory to other worker processes. My original code looks like this:
# Note: this version DOES NOT work.
cluster = tf.train.ClusterSpec(...)
server = tf.train.Server(cluster, job_name = job_name, task_index = task_index)
if job_name == "ps":
# Do something for parameter server.
...
elif job_name == "worker":
# Worker.
with tf.device(tf.train.replica_device_setter(worker_device = "/job:worker/task:" + str(task_index), cluster = cluster)):
# Build your network model here.
...
# GPU configuration.
gpu_options = tf.GPUOptions(per_process_gpu_memory_fraction = PER_PROCESS_GPU_MEMORY_FRACTION)
config = tf.ConfigProto(gpu_options = gpu_options)
with tf.train.MonitoredTrainingSession(
master = server.target,
is_chief = (task_index == 0),
config = config
) as sess:
# Logic part of the worker.
...
It turns out that the GPU configuration should be defined in the tf.train.Server(). So the correct version should be:
# GPU configuration.
gpu_options = tf.GPUOptions(per_process_gpu_memory_fraction = PER_PROCESS_GPU_MEMORY_FRACTION)
config = tf.ConfigProto(gpu_options = gpu_options)
cluster = tf.train.ClusterSpec(cluster_dict)
server = tf.train.Server(cluster, job_name = job_name, task_index = task_index, config = config)
if job_name == "ps":
# Do something for parameter server.
...
elif job_name == "worker":
# Worker.
with tf.device(tf.train.replica_device_setter(worker_device = "/job:worker/task:" + str(task_index), cluster = cluster)):
# Build your network model here.
...
with tf.train.MonitoredTrainingSession(
master = server.target,
is_chief = (task_index == 0)
) as sess:
# Logic part of the worker.
...
Releasing GPU Memory
When a worker finishes its task, it will not release the allocated GPU memory by default. To solve this problem, we need to make small modifications in the code:
if job_name == "ps":
# Parameter server.
...
elif job_name == "worker":
# Worker.
...
# Release memory when a worker is finished.
tf.contrib.keras.backend.clear_session()
All we need is to add tf.contrib.keras.backend.clear_session() at the end so that the worker can release GPU memory.
Saving with Monitored Session
I encountered the saving issue when I try to save the model parameters as usual:
# Note: this version DOES NOT work.
with tf.train.MonitoredTrainingSession(...) as sess:
# Logic part of the worker.
...
# Save the network parameters.
saver = tf.train.Saver(var_list = ...)
saver.save(sess, file_name)
It turns out that in tf.train.MonitoredTrainingSession() you can only save models using sess._sess._sess._sess._sess:
with tf.train.MonitoredTrainingSession(...) as sess:
# Logic part of the worker.
...
# Save the network parameters.
saver = tf.train.Saver(var_list = ...)
saver.save(sess._sess._sess._sess._sess, file_name)
Performance
Next I will compare the performance of standard and asynchronous implementation of DQN. In both experiments, the agent is trained to play the Atari game “Pong” since this is a simple environment which can be easily solved by exploiting the weakness of the computer-controlled opponent.
Learning Curves
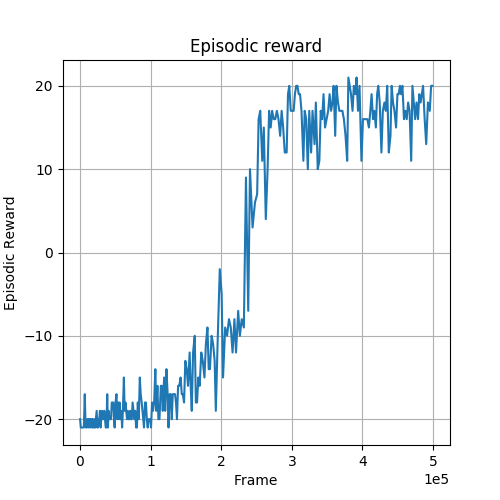
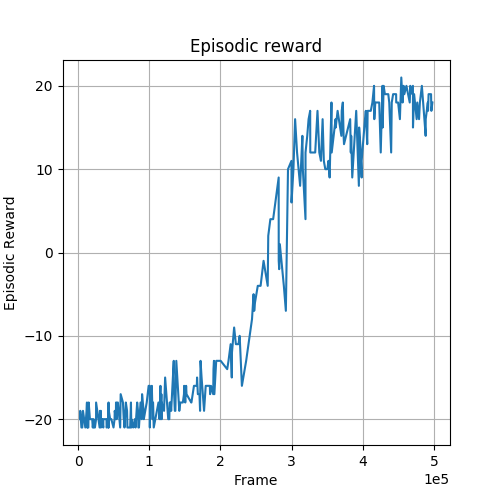
Fig. 1 and Fig. 2 show the learning curves with respect to the episodic reward during training. Higher is better. We can see that the agent is able to learn slightly faster with standard implementation. This is probably because in standard implementation the gradients are always up-to-date while in asynchronous implementation there is some delay for gradients updating.
Training Time
Both experiments are conducted under a g3.4xlarge instance (by using Amazon Web Service). 10 worker processes are created for the asynchronous implementation. The training time is shown in the following table. Lower is faster.
| Variant | Time(s) |
|---|---|
| Standard | 12812 |
| Asynchronous | 5523 |
This shows that asynchronous implementation gets a huge speed boost.
Conclusion
In this blog I shared my personal experience of asynchronous implementation using distributed TensorFlow. Even though the experiments are conducted under some reinforcement learning task (DQN), I believe that similar experiment results should still apply to other deep learning tasks, that is, asynchronous implementation gets a huge speed boost in exchange of some convergence speed loss.
Resources
- Source code for this experiment:
- Further reference: